Quick Summary
- Conventional wisdom holds that our eyes pay attention to parts of a scene that stand out
- New study shows attention is guided by "meaning" instead
- "Meaning maps" of scenes were constructed by crowdsourcing
Our visual attention is drawn to parts of a scene that have meaning, rather than to those that are salient or “stick out,” according to new research from the Center for Mind and Brain at the University of California, Davis. The findings, published Sept. 25 in the journal Nature Human Behavior, overturn the widely-held model of visual attention.
“A lot of people will have to rethink things,” said psychology professor John Henderson, who led the research. “The saliency hypothesis really is the dominant view.”
Our eyes perceive a wide field of view in front of us, but we only focus our attention on a small part of this field. How do we decide where to direct our attention, without thinking about it?
The dominant theory in attention studies is “visual salience,” Henderson said. Salience means things that “stick out” from the background, like colorful berries on a background of leaves or a brightly lit object in a room.
Saliency is relatively easy to measure. You can map the amount of saliency in different areas of a picture by measuring relative contrast or brightness, for example.
Henderson called this the “magpie theory": Our attention is drawn to bright and shiny objects.
“It becomes obvious, though, that it can’t be right,” he said, otherwise we would constantly be distracted.
Making a map of meaning
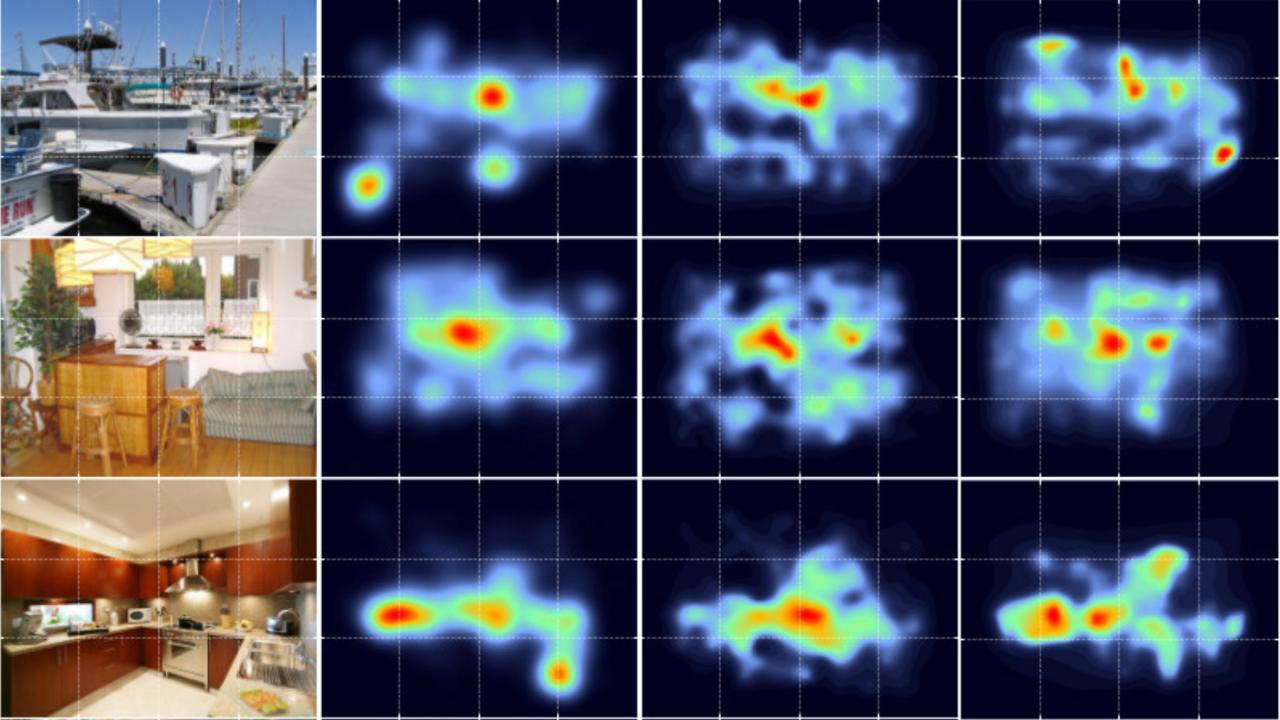
Henderson and postdoctoral researcher Taylor Hayes set out to test whether attention is guided instead by how “meaningful” we find an area within our view. They first had to construct “meaning maps” of test scenes, where different parts of the scene had different levels of meaning to an observer.
To make their meaning maps, Henderson and Hayes took images of scenes, broke them up into overlapping circular tiles and submitted the individual tiles to the online crowdsourcing service Mechanical Turk, asking users to rate the tiles for meaning.
Based on the voting results, the researchers assigned levels of meaning to different areas of images and created meaning maps comparable to saliency maps of the same scenes.
Next, they tracked the eye movements of volunteers as they looked at the scenes. Those eyetracks gave them maps of what parts of images attracted the most attention. These “attention maps” were closer to the meaning maps than the saliency maps, Henderson said.
In search of meaning
Henderson and Hayes don’t yet have firm data on what makes part of a scene meaningful, although they have some ideas. For example, a cluttered table or shelf attracted more attention than a highly salient splash of sunlight on a wall. With further work, they hope to develop a “taxonomy of meaning,” Henderson said.
Although the research is aimed at a fundamental understanding of how visual attention works, there could be some near-term applications, Henderson said, for example, in developing automated visual systems that allow computers to scan security footage or to automatically identify or caption images online.
The work was supported by the National Science Foundation.
Listen to this story on our podcast, Three Minute Egghead
Media Resources
Andy Fell, News and Media Relations, 530-752-4533, ahfell@ucdavis.edu
John Henderson, Center for Mind and Brain, johnhenderson@ucdavis.edu